DMA 和 Cache 一致性问题相关知识点
DMACachepgprot_noncached
关于代码深入分析见DMA 相关概念以及 arm 实现
DMA
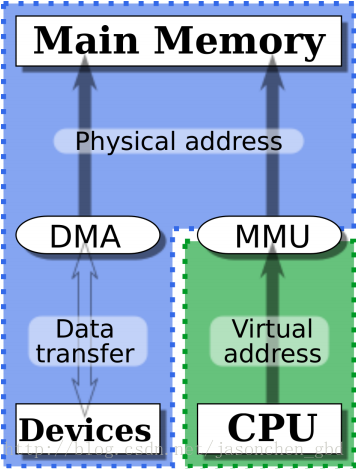
DMA(Direct memory access) 直接内存访问是一种硬件机制,它允许 外围设备 和 主内存 之间直接传输它们的 I/O 数据,而不需要 CPU 的参与。使用这种机制可以大大提高与设备通信的吞吐量
DMA 方式的数据传输由 DMA 控制器 (DMAC) 控制,在传输期间 CPU 可以并发地执行其他任务,当 DMA 结束后, DMAC 通过中断通知 CPU 数据传输已经结束,然后由 CPU 执行相应的中断服务程序进行后续处理
Cache 和不一致性问题
Cache 即高速缓冲存储器,是一种特殊的存储器子系统,其中复制了频繁使用的数据以利于快速访问。
假设 DMA 针对内存的目的地址和 Cache 缓存的对象没有重叠区域, DMA 和 Cache 之间就相安无事,但是,如果有重叠呢,经过 DMA 操作, Cache 缓存对应的内存的数据已经被修改,而 CPU 本身并不知道,它仍然认为 Cache 中的数据仍然还是内存中的数据,以后访问 Cache 映射的内存时,它仍然使用陈旧的 Cache 数据,这就会发生 Cache 与 内存 之间数据 不一致性 的错误。
最简单的方法是直接禁止 DMA 目标地址范围内内存的 Cache 功能,当然这是牺牲性能的,但却高可靠。
Cache 带来的高效率与 一致性问题 需要平衡
只要 Cache 的空间与主存空间在一定范围内保持适当比例的映射关系, Cache 的命中率还是相当高的。一般规定 Cache 与内存的空间比为 4:1000,即 128kB Cache 可映射 32MB 内存; 256kB Cache 可映射 64MB 内存。在这种情况下。命中率都在 90% 以上。至于没有命中的数据, CPU 只好直接从内存获取。获取的同时,也把它拷进 Cache。
工作模式
cache 有两种工作模式
wirte through,CPU对主存写数据时,不经过cache直接写到内存,此时对于写的实现比较简单,如果系统只用写穿模式的话,cache则变成了读缓存write back,CPU写入数据时,不直接将数据写入内存,而是写入cache,当cache数据被替换出去或者系统做cache flush时才写回主存
Cache 接口
Flush,把Cache内容写回Main Memory, 当Cache为Write through, 不需要FlushInvalidate,把Cache内容直接丢掉不要
Cache 使用场景
当有 DMA 在使用 Main Memory 的时候,一般要用到 cache 的处理。因为 DMA 在访问 Main Memory 时是不经过 cache 的。比较典型的比如在 Ethernet, wireless, USB 等驱动中, DMA 会操作 descriptors 和 packet buffers,驱动需要实现如下:
- 如果
Driver使用descripter和packet buffer的地址都是cache的地址,那么Driver在读 descripter里一些状态比如Owned by CPU/DMA,有没有收到包时,要对descripter当前结构里的内容做cache invalidate,收到packet后,也要对packet buffer做cache invalidateDriver在写 descripter里一些状态比如Owned by DMA,要发送包时,要对descripter当前结构里的内容做cache flush,发送packet时,也要对packet buffer做 cache flush
- 有些
Driver会对descripter使用uncache 地址,那么上面两种情况里invalidate/flush就不用做了。一般很少会对packet buffer也用uncache 地址的,因为对packet内容的处理将会很频繁,使用uncache会很慢。而descripter一般由于结构比较小,如果也使用cache地址的话,做invalidate/flush的时间消耗可能会比uncache的还要多。
DMA 映射
因此在 DMA 是否使用 cache 的问题上,可以根据 DMA 缓冲区期望保留的的时间长短来决策。根据 DMA 缓冲区期望保留的时间长短,区分两种类型的 DMA 映射:
一致性 DMA 映射 (Coherent DMA buffers)一致性 DMA 映射申请的缓存区不使用 cache,因此可以保持 cache 一致性。一致性映射具有很长的生命周期,在这段时间内占用的映射寄存器,即使不使用也不会释放。生命周期为该驱动的生命周期流式 DMA 映射流式 DMA 映射实现比较复杂。生命周期比较短,而且使用 cache,需要处理一致性问题。一些硬件对流式映射有优化。建立流式 DMA 映射,需要告诉内核数据的流动方向DMA从外设读取数据到供处理器使用时,可先invalidate操作。这样将迫使处理器在读取cache中的数据时,先从内存中读取数据到缓存,保证缓存和内存中数据的一致性DMA向外设写入由处理器提供的数据时,可先writeback操作。这样可以DMA传输数据之前先将缓存中的数据写回到内存中- 如果不清楚
DMA操作的方向,也可先同时进行invalidate和writeback操作。操作的结果等同于invalidate和writeback操作效果的和。
一致性 DMA 映射
dma_alloc_coherent() 首先分配一组连续的物理页用作后续 DMA 操作的缓冲区,然后在软件层面将该段物理地址空间重新映射到非缓存的虚拟地址空间,具体来说在页目录和页表项中关闭了这段映射区间上的 cache 功能,使得 cache 的一致性问题不再成为问题。因为关闭了 cache,失去了高速缓存功能,所以一致性映射在性能上打了折扣。
流式 DMA 映射
在 流式 DMA 映射 场合, DMA 传输通道所使用的缓冲区往往不是由当前驱动程序自身分配的,而且往往每次 DMA 传输都会重新建立一个 流式映射的缓冲区。此外,由于无法确定外部模块传入的 DMA 缓冲区的映射情况,所以设备驱动程序必须小心地处理可能会出现的 cache 一致性问题。
需要注意的是,在某些平台上,比如 ARM,** CPU 的读 / 写用的是不同的 cache(读用的是 cache,写则用的是 write buffer ),所以建立 流式 DMA 映射 需要指明数据在 DMA 通道中的流向,以便由内核决定是操作 cache 还是 write buffer。**
pgprot_noncached
arch:arm
pgprot_noncached() 是一个宏,它实际上禁止了相关页的 cache 和写缓冲 (write buffer), 另外一个稍微少的一些限制的宏是:
pgprot_writecombine(prot) 它则没有禁止写缓冲
#define pgprot_noncached(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED)
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE)