由于内核栈的大小是有限的,就会有发生溢出的可能,比如调用嵌套太多、参数太多都会导致内核栈的使用超出设定的大小。本文分析内核栈溢出。
Linux 系统进程运行分为 用户态 和 内核态,进入内核态之后使用的是内核栈,作为基本的安全机制,用户程序不能直接访问内核栈,所以尽管内核栈属于进程的地址空间,但与用户栈是分开的。内核栈需要方便快捷的访问用户态进程信息 thread_info,这部分数据就压在内核栈的底部,大小默认为 16Kb。如下图所示:
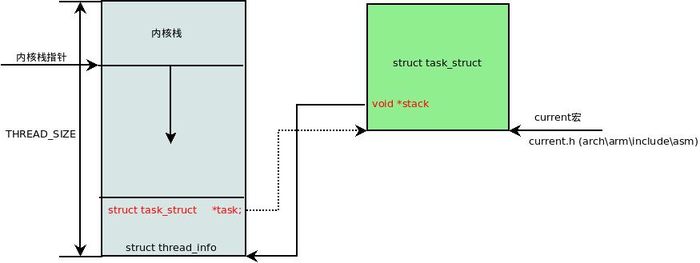
内核栈溢出的结果往往是系统崩溃,因为溢出会覆盖掉本不该触碰的数据,首当其冲的就是 thread_info — 它就在内核栈的底部,内核栈是从高地址往低地址生长的,一旦溢出首先就破坏了 thread_info,thread_info 里存放着指向进程的指针等关键数据,迟早会被访问到,那时系统崩溃就是必然的事。
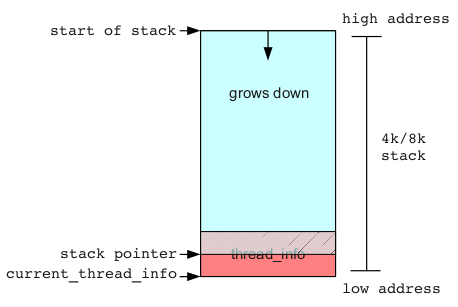
内核栈溢出导致的系统崩溃有时会被直接报出来,比如你可能会看到:
...
Call Trace:
[<ffffffff8106e3e7>] ? warn_slowpath_common+0x87/0xc0
BUG: unable to handle kernel NULL pointer dereference at 00000000000009e8
IP: [<ffffffff8100f4dd>] print_context_stack+0xad/0x140
PGD 5fdb8ae067 PUD 5fdbee9067 PMD 0
Thread overran stack, or stack corrupted
Oops: 0000 [#1] SMP
...但更多的情况是不直接报错,而是各种奇怪的 panic。在分析 vmcore 的时候,它们的共同点是 thread_info 被破坏了。
以下是一个实例,注意在 task_struct 中 stack 字段直接指向内核栈底部也就是 thread_info 的位置,我们看到 thread_info 显然被破坏了:cpu 的值大得离谱,而且指向 task 的指针与 task_struct 的实际地址不匹配:
crash64> struct task_struct ffff8800374cb540
struct task_struct {
state = 2,
stack = 0xffff8800bae2a000,
...
crash64> thread_info 0xffff8800bae2a000
struct thread_info {
task = 0xffff8800458efba0,
exec_domain = 0xffffffff,
flags = 0,
status = 0,
cpu = 91904,
preempt_count = 0,
...作为一种分析故障的手段,可以监控内核栈的大小和深度,方法如下:
# mount -t debugfs nodev /sys/kernel/debug
# echo 1 > /proc/sys/kernel/stack_tracer_enabled然后检查下列数值,可以看到迄今为止内核栈使用的峰值和对应的 backtrace:
# cat /sys/kernel/debug/tracing/stack_max_size
# cat /sys/kernel/debug/tracing/stack_trace