本文介绍 Linux 下进程地址空间及其内存分布
进程地址空间
对于一个进程,其空间分布如下图:
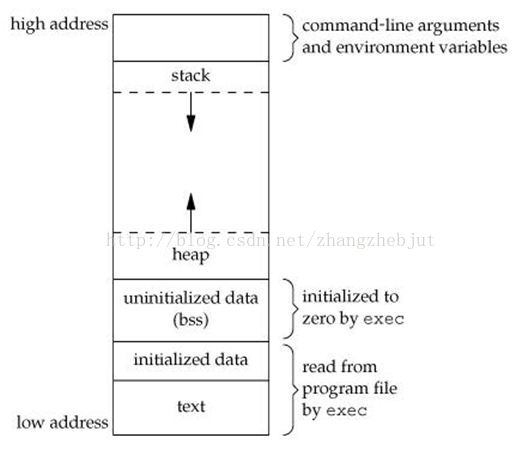
内核空间和用户空间
Linux 的虚拟地址空间范围为 0~4G,Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF)供各个进程使用,称为 用户空间。因为每个进程可以通过系统调用进入内核,因此,Linux 内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有 4G 字节的虚拟空间。
Linux 使用两级保护机制:0 级供内核使用,3 级供用户程序使用,每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的,最高的 1GB 字节虚拟内核空间则为所有进程以及内核所共享。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。 虽然内核空间占据了每个虚拟空间中的最高 1GB 字节,但映射到物理内存却总是从最低地址(0x00000000),另外,使用虚拟地址可以很好的保护内核空间被用户空间破坏,虚拟地址到物理地址转换过程有操作系统和 CPU 共同完成(操作系统为 CPU 设置好页表,CPU 通过 MMU 单元进行地址转换)。
多任务操作系统中的每一个进程都运行在一个属于它自己的内存沙盒中,这个沙盒就是虚拟地址空间(virtual address space),在 32 位模式下,它总是一个 4GB 的内存地址块。这些虚拟地址通过页表(page table)映射到物理内存,页表由操作系统维护并被处理器引用。每个进程都拥有一套属于它自己的页表。
在 Linux 中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存,内核代码和数据总是可寻址的,随时准备处理中断和系统调用。与之相反,用户模式地址空间的映射随着进程切换的发生而不断的变化,如下图所示:
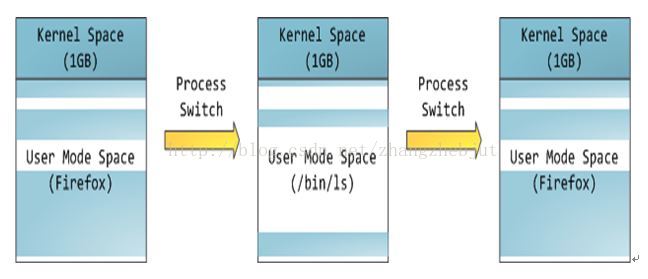
上图中蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。
进程内存布局
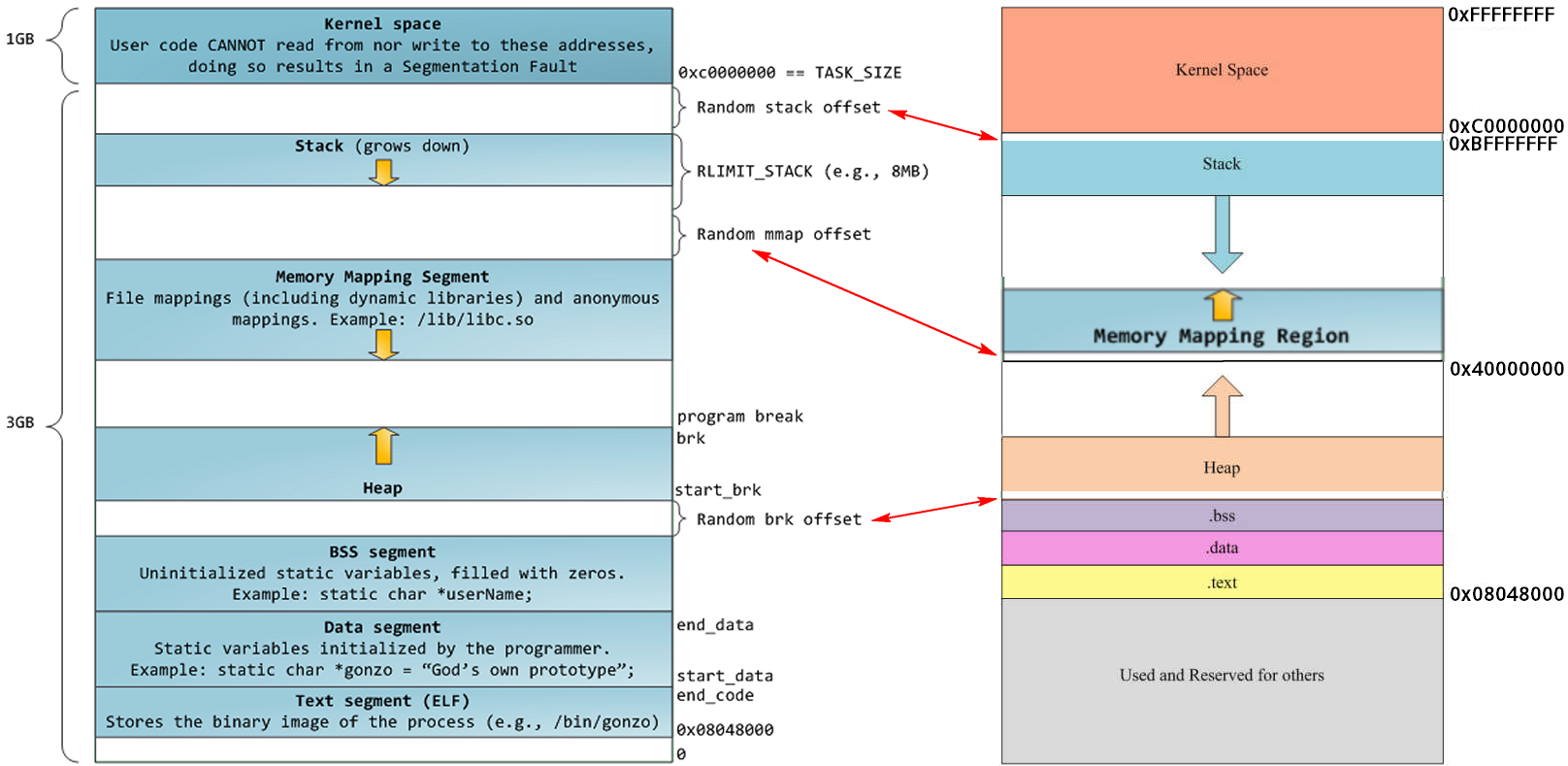
随机偏移量是为了防止漏洞攻击,但不幸的是,32 位地址空间相当紧凑,这给随机化所留下的空间不大,削弱了这种技巧的效果。
进程栈
通过不断向栈中压入数据,超出其容量就会耗尽栈所对应的内存区域,这将触发一个页故障(page fault),而被 Linux 的 expand_stack() 处理,它会调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。如果栈的大小低于 RLIMIT_STACK(通常为 8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情。这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会栈溢出(stack overflow),程序收到一个段错误(segmentation fault)。
内存映射段
Linux 通过 mmap 系统调用来请求这种映射。在 Linux 中,使用 malloc 申请一块比 MMAP_THRESHOLD 还大的内存时,C 运行库将会创建这样一个匿名映射而不是使用堆内存。
堆
与栈一样,堆用于运行时内存分配;但不同的是,堆用于存储那些生存期与函数调用无关的数据。
在 C 语言中,堆分配的接口是 malloc() 函数。如果堆中有足够的空间来满足内存请求,它就可以被语言运行时库处理而不需要内核参与,否则,堆会被扩大,通过 brk() 系统调用来分配请求所需的内存块。堆管理是很复杂的,需要精细的算法来应付我们程序中杂乱的分配模式,优化速度和内存使用效率。
BSS 和数据段
BSS 保存的是未被初始化的静态变量内容
数据段保存在源代码中已经初始化的静态变量的内容。数据段不是匿名的,它映射了一部分的程序二进制镜像,也就是源代码中指定了初始值的静态变量。
Example
#include<stdio.h>
#include <malloc.h>
void print(char *,int);
int main()
{
char *s1 = "abcde"; //"abcde"作为字符串常量存储在常量区 s1、s2、s5 拥有相同的地址
char *s2 = "abcde";
char s3[] = "abcd";
long int *s4[100];
char *s5 = "abcde";
int a = 5;
int b = 6;//a,b 在栈上,&a>&b 地址反向增长
printf("variables address in main function: s1=%p s2=%p s3=%p s4=%p s5=%p a=%p b=%p \n",
s1,s2,s3,s4,s5,&a,&b);
printf("variables address in processcall:n");
print("ddddddddd",5);// 参数入栈从右至左进行,p 先进栈,str 后进 &p>&str
printf("main=%p print=%p \n",main,print);
// 打印代码段中主函数和子函数的地址,编译时先编译的地址低,后编译的地址高 main<print
}
void print(char *str,int p)
{
char *s1 = "abcde"; //abcde 在常量区,s1 在栈上
char *s2 = "abcde"; //abcde 在常量区,s2 在栈上 s2-s1=6 可能等于 0,编译器优化了相同的常量,只在内存保存一份
// 而 &s1>&s2
char s3[] = "abcdeee";//abcdeee 在常量区,s3 在栈上,数组保存的内容为 abcdeee 的一份拷贝
long int *s4[100];
char *s5 = "abcde";
int a = 5;
int b =6;
int c;
int d; //a,b,c,d 均在栈上,&a>&b>&c>&d 地址反向增长
char *q=str;
int m=p;
char *r=(char *)malloc(1);
char *w=(char *)malloc(1) ; // r<w 堆正向增长
printf("s1=%p s2=%p s3=%p s4=%p s5=%p a=%p b=%p c=%p d=%p str=%p q=%p p=%p m=%p r=%p w=%p \n",
s1,s2,s3,s4,s5,&a,&b,&c,&d,&str,q,&p,&m,r,w);
/* 栈和堆是在程序运行时候动态分配的,局部变量均在栈上分配。
栈是反向增长的,地址递减;malloc 等分配的内存空间在堆空间。堆是正向增长的,地址递增。
r,w 变量在栈上(则 &r>&w),r,w 所指内容在堆中(即 r<w)。*/
}