转载自(http://kyang.cc/)[http://kyang.cc/]
Linux 中有各种栈,进程栈、线程栈、内核栈、中断栈,讲述这几种栈的作用及位置
进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
栈是什么?栈有什么作用?
首先,栈 (stack) 是一种串列形式的 数据结构。这种数据结构的特点是 后入先出 (LIFO, Last In First Out),数据只能在串列的一端 (称为:栈顶 top) 进行 推入 (push) 和 弹出 (pop) 操作。根据栈的特点,很容易的想到可以利用数组,来实现这种数据结构。但是本文要讨论的并不是软件层面的栈,而是硬件层面的栈。
大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。例如在 ARM 架构上,R13 (SP) 指针是堆栈指针寄存器,而 PUSH 是用于压栈的汇编指令,POP 则是出栈的汇编指令。
栈作用可以从两个方面体现:函数调用 和 多任务支持
函数调用
我们知道一个函数调用有以下三个基本过程:
- 调用参数的传入
- 局部变量的空间管理
- 函数返回
函数的调用必须是高效的,而数据存放在 CPU通用寄存器 或者 RAM 内存 中无疑是最好的选择。以传递调用参数为例,我们可以选择使用 CPU通用寄存器 来存放参数。但是通用寄存器的数目都是有限的,当出现函数嵌套调用时,子函数再次使用原有的通用寄存器必然会导致冲突。因此如果想用它来传递参数,那在调用子函数前,就必须先 保存原有寄存器的值,然后当子函数退出的时候再 恢复原有寄存器的值。
函数的调用参数数目一般都相对少,因此通用寄存器是可以满足一定需求的。但是局部变量的数目和占用空间都是比较大的,再依赖有限的通用寄存器未免强人所难,因此我们可以采用某些 RAM 内存区域来存储局部变量。但是存储在哪里合适?既不能让函数嵌套调用的时候有冲突,又要注重效率。
这种情况下,栈无疑提供很好的解决办法:
- 对于通用寄存器传参的冲突,我们可以再调用子函数前,将通用寄存器临时压入栈中;在子函数调用完毕后,在将已保存的寄存器再弹出恢复回来
- 而局部变量的空间申请,也只需要向下移动下栈顶指针;将栈顶指针向回移动,即可就可完成局部变量的空间释放
- 对于函数的返回,也只需要在调用子函数前,将返回地址压入栈中,待子函数调用结束后,将函数返回地址弹出给 PC 指针,即完成了函数调用的返回
于是上述函数调用的三个基本过程,就演变记录一个栈指针的过程。每次函数调用的时候,都配套一个栈指针。即使循环嵌套调用函数,只要对应函数栈指针是不同的,也不会出现冲突。
典型函数栈帧:
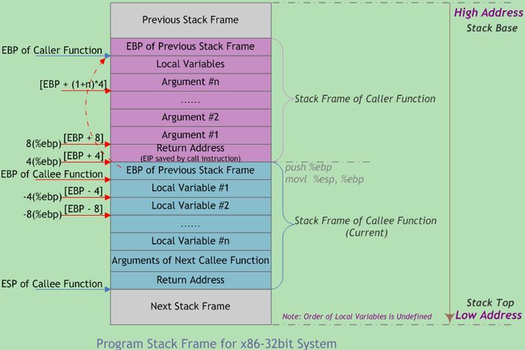
多任务支持
栈的意义还不只是函数调用,有了它的存在,才能构建出操作系统的多任务模式。
Linux 中有几种栈?各种栈的内存位置?
内核将栈分成四种:
- 进程栈
- 线程栈
- 内核栈
- 中断栈
进程栈
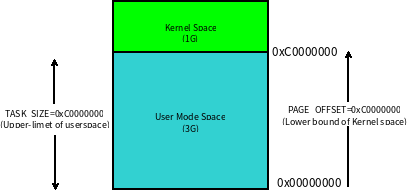
进程栈是属于用户态栈,和进程 虚拟地址空间 (Virtual Address Space) 密切相关。那我们先了解下什么是虚拟地址空间:在 32 位机器下,虚拟地址空间大小为 4G。这些虚拟地址通过页表 (Page Table) 映射到物理内存,页表由操作系统维护,并被处理器的内存管理单元 (MMU) 硬件引用。每个进程都拥有一套属于它自己的页表,因此对于每个进程而言都好像独享了整个虚拟地址空间。
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
- 程序段 (Text Segment):可执行文件代码的内存映射
- 数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
- BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
- 堆区 (Heap) : 存储动态内存分配,匿名的内存映射
- 栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
- 映射段(Memory Mapping Segment):任何内存映射文件
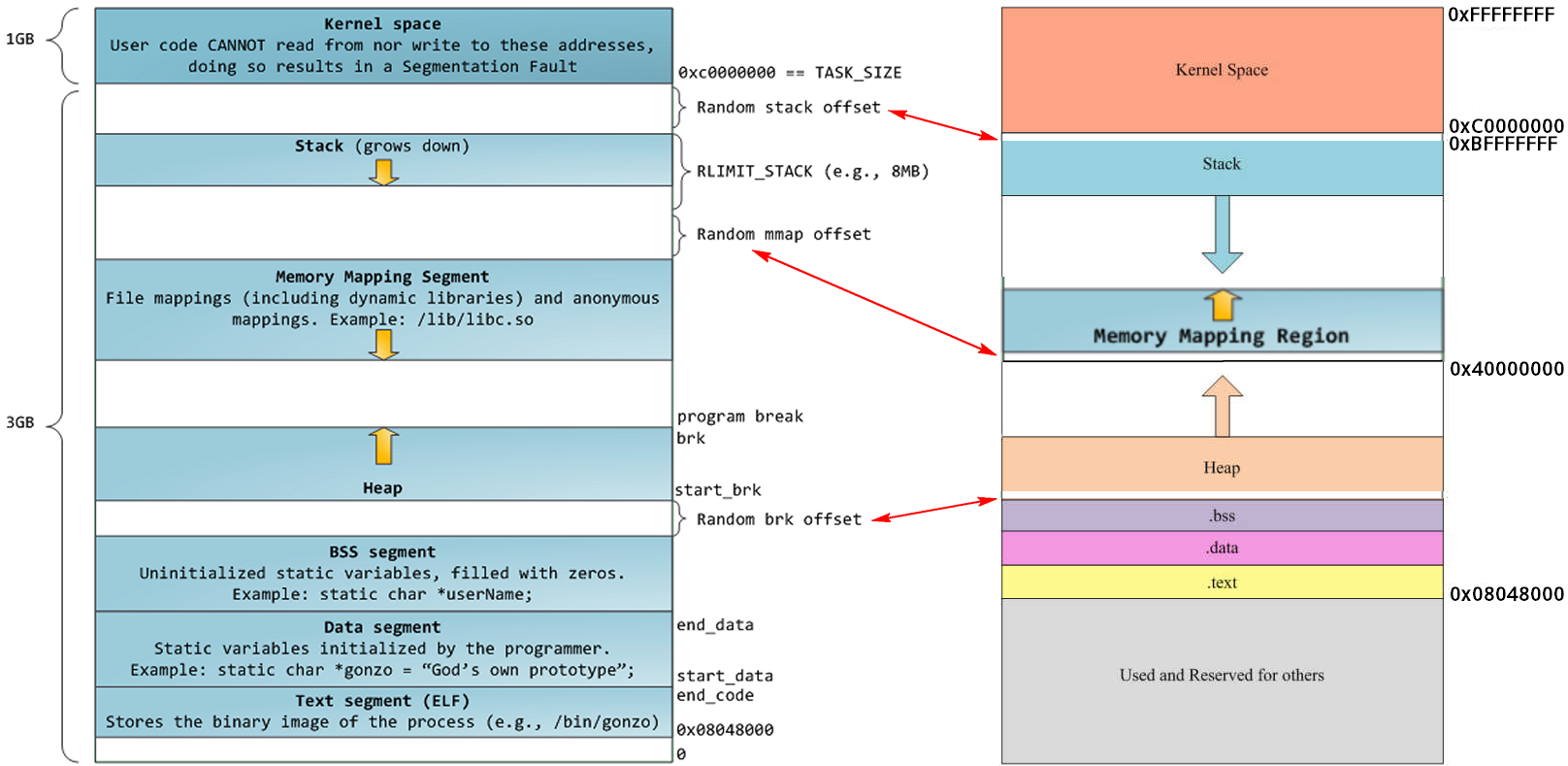
而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
如何确定进程栈大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}$ g++ -g stacksize.c -o ./stacksize
$ gdb ./stacksize
(gdb) r
Starting program: /home/home/misc-code/setrlimit
Program received signal SIGSEGV, Segmentation fault.
blow_stack () at setrlimit.c:4
4 blow_stack();
(gdb) print (void *)$esp
$1 = (void *) 0xffffffffff7ff000
(gdb) print (void *)orig_stack_pointer
$2 = (void *) 0xffffc800
(gdb) print 0xffffc800-0xff7ff000
$3 = 8378368 // Current Process Stack Size is 8MLinux内核内存布局
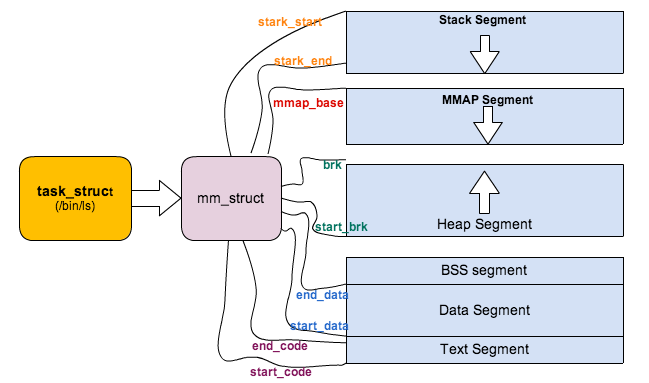
内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的进程内存段布局图一起看:
include/linux/mm_types.h
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
unsigned long mmap_base; /* memory mapping段的起始地址 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
进程栈的动态生长
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK,那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
线程栈
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
最初的进程定义都包含程序、资源及其执行三部分,其中程序通常指代码,资源在操作系统层面上通常包括内存资源、IO资源、信号处理等部分,而程序的执行通常理解为执行上下文,包括对cpu的占用,后来发展为线程。
在线程概念出现以前,为了减小进程切换的开销,操作系统设计者逐渐修正进程的概念,逐渐允许将进程所占有的资源从其主体剥离出来,允许某些进程共享一部分资源,例如文件、信号,数据内存,甚至代码,这就发展出轻量进程的概念。
在 do_fork() 中,不同的 clone_flags 将导致不同的行为,对于LinuxThreads,glibc使用如下参数来调用clone()创建”线程”
int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID | CLONE_SYSVSEM
#if __ASSUME_NO_CLONE_DETACHED == 0
| CLONE_DETACHED
#endif
| 0);Linux内核在2.0.x版本就已经实现了轻量进程,应用程序可以通过一个统一的clone()系统调用接口,用不同的参数指定创建轻量进程还是普通进程。在内核中,clone()调用经过参数传递和解释后会调用do_fork(),这个核内函数同时也是fork()、vfork()系统调用的最终实现:
kernel/fork.c
do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
{
...
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
...
}虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。
然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的nptl/allocatestack.c 中的 allocate_stack() 函数中看到:
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
内核栈
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。
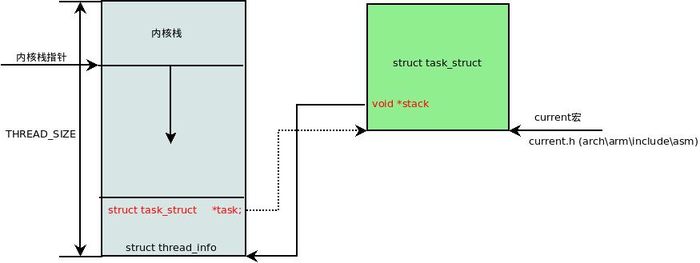
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
中断栈
进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中(如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。
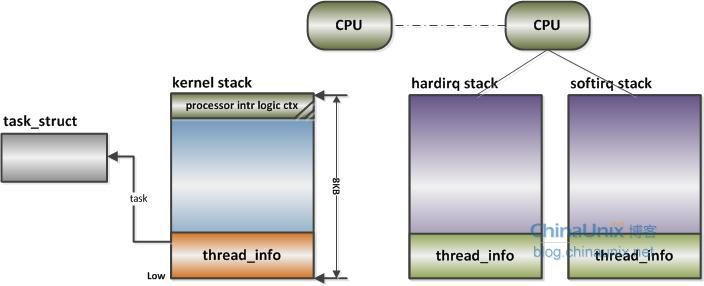
而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。
Linux 为什么需要区分这些栈?
为什么需要区分这些栈,其实都是设计上的问题。
为什么需要单独的进程内核栈?
所有进程运行的时候,都可能通过系统调用陷入内核态继续执行。假设第一个进程 A 陷入内核态执行的时候,需要等待读取网卡的数据,主动调用 schedule() 让出 CPU;此时调度器唤醒了另一个进程 B,碰巧进程 B 也需要系统调用进入内核态。那问题就来了,如果内核栈只有一个,那进程 B 进入内核态的时候产生的压栈操作,必然会破坏掉进程 A 已有的内核栈数据;一但进程 A 的内核栈数据被破坏,很可能导致进程 A 的内核态无法正确返回到对应的用户态了
为什么需要单独的线程栈?
Linux 调度程序中并没有区分线程和进程,当调度程序需要唤醒”进程”的时候,必然需要恢复进程的上下文环境,也就是进程栈;但是线程和父进程完全共享一份地址空间,如果栈也用同一个那就会遇到问题